
07313 KI und Datenschutz rechtskonform umsetzen
|
Setzen Sie künstliche Intelligenz (KI) rechtskonform ein! In diesem Beitrag diskutieren wir die datenschutzrechtlichen Herausforderungen entlang des Lebenszyklus von KI-Systemen. Erfahren Sie, wie Sie „Privacy by Design” und „Security by Design” in Ihre Prozesse integrieren und die Risiken der Datenverarbeitung minimieren. Praxisnahe Tipps und detaillierte Analysen helfen Ihnen, Datenschutz und KI erfolgreich in Einklang zu bringen. Arbeitshilfen: von: |
1 Übersicht über die Datenverarbeitung im Lebenszyklus von generativen KI-Systemen
Bei der datenschutzrechtlichen Einordnung von künstlicher Intelligenz ist es essenziell, alle Verarbeitungsphasen im Rahmen das Lebenszyklus einer KI zu betrachten. Es ist also eine ganzheitliche Betrachtung der Verarbeitung vorzunehmen. Dies spielt sowohl für KI-Entwickler und KI-Anbieter als auch für Unternehmen eine Rolle, die die KI-Anwendung bei sich einsetzen wollen. Verantwortliche sind datenschutzrechtlich verpflichtet, „Privacy und Security by Design” im erforderlichen Rahmen in ihren Geschäftsprozessen zu berücksichtigen. Dazu sollte man sich zuerst einmal kurz die wesentlichen Stationen im Lebenszyklus von (generativen) KI-Systemen vergegenwärtigen.
Rechtskonformität je Lebenszyklus
Zwar ist das Lernen der wichtigste Unterschied zwischen KI und der traditionellen Datenverarbeitung. Jedoch steht diese Phase nicht komplett isoliert da, sondern ist die Basis für die nachfolgenden Datenverarbeitungen, weshalb diese immer auch in den Gesamtkontext der KI-Verarbeitung eingebunden werden muss. Daher sind bei der Beurteilung der Rechtskonformität eines KI-Einsatzes der gesamte Lebenszyklus einer KI-Anwendung sowie der damit in Verbindung stehende Datenlebenszyklus zu berücksichtigen. Im Folgenden werden kurz die vier grundsätzlichen Phasen der KI-Verarbeitung im Rahmen der KI-Lebenszyklen beschrieben und im Anschluss jeweils getrennt aus datenschutzrechtlicher Sicht näher thematisiert.
Zwar ist das Lernen der wichtigste Unterschied zwischen KI und der traditionellen Datenverarbeitung. Jedoch steht diese Phase nicht komplett isoliert da, sondern ist die Basis für die nachfolgenden Datenverarbeitungen, weshalb diese immer auch in den Gesamtkontext der KI-Verarbeitung eingebunden werden muss. Daher sind bei der Beurteilung der Rechtskonformität eines KI-Einsatzes der gesamte Lebenszyklus einer KI-Anwendung sowie der damit in Verbindung stehende Datenlebenszyklus zu berücksichtigen. Im Folgenden werden kurz die vier grundsätzlichen Phasen der KI-Verarbeitung im Rahmen der KI-Lebenszyklen beschrieben und im Anschluss jeweils getrennt aus datenschutzrechtlicher Sicht näher thematisiert.
Verarbeitungsschritte separat betrachten
Besonders bei komplexen KI-Systemen mit umfangreichen, intransparenten Verarbeitungsprozessen kommt es häufig vor, dass die jeweiligen Verarbeitungsschritte separat voneinander betrachtet werden müssen. Es kann durchaus sein, dass für die jeweiligen Verarbeitungsschritte unterschiedliche Legitimationen herangezogen werden müssen, da die Legitimation für die vorhergehende Verarbeitung nicht mehr für die nachfolgende Verarbeitungstätigkeit zutrifft, insbesondere wenn man in der neuen Verarbeitung eine „Zweckänderung” sehen kann oder sich die Verantwortlichkeiten für die jeweilige Datenverarbeitung ändern bzw. erweitern.
Besonders bei komplexen KI-Systemen mit umfangreichen, intransparenten Verarbeitungsprozessen kommt es häufig vor, dass die jeweiligen Verarbeitungsschritte separat voneinander betrachtet werden müssen. Es kann durchaus sein, dass für die jeweiligen Verarbeitungsschritte unterschiedliche Legitimationen herangezogen werden müssen, da die Legitimation für die vorhergehende Verarbeitung nicht mehr für die nachfolgende Verarbeitungstätigkeit zutrifft, insbesondere wenn man in der neuen Verarbeitung eine „Zweckänderung” sehen kann oder sich die Verantwortlichkeiten für die jeweilige Datenverarbeitung ändern bzw. erweitern.
Vier Schritte der Verarbeitung
Jeder einzelne Verarbeitungsschritt muss berücksichtigt werden, um sicherzustellen, dass der Einsatz im Gesamtkontext über den gesamten Datenlebenszyklus rechtskonform ist. Die Datenverarbeitung bei generativen KI-Systemen kann in vier Abschnitte unterteilt werden (vgl. [1]).
Jeder einzelne Verarbeitungsschritt muss berücksichtigt werden, um sicherzustellen, dass der Einsatz im Gesamtkontext über den gesamten Datenlebenszyklus rechtskonform ist. Die Datenverarbeitung bei generativen KI-Systemen kann in vier Abschnitte unterteilt werden (vgl. [1]).
1.1 Sammlung/Aggregation/Veredelung (Aufbereitung) von Daten
Der erste Schritt besteht in der Sammlung von Daten, also der Datenaggregation. Es wird dabei in der Regel ein großer Datensatz mit entsprechenden Beispielen für die Art der zu erstellenden Inhalte gesammelt. Bei der Datensammlung ist, wie nachfolgend nochmal detailliert ausgeführt wird, darauf zu achten, dass diese Daten so unverfälscht und präzise wie möglich den jeweiligen Sachverhalt widerspiegeln.
Gerade weil Daten aufgrund der mit ihnen in einem Kontext stehenden Daten eine Vielzahl an Informationen enthalten können, die die KI möglicherweise auf eine falsche Spur setzen würden, sind die Trainingsdaten so zu verändern und bereits gesammelte Daten bzw. Dokumente entsprechend so aufzubereiten, dass sie sich für das nachfolgende Training eignen und möglichst wenig Informationen streuen.
Eine solche Sammlung kann z. B. aus einem umfangreichen Datensatz mit mannigfaltigen Bildern oder Texten bestehen, um damit die (generative) KI so zu trainieren, dass sie in die Lage versetzt wird, basierend auf diesen Daten realistische Bilder oder kohärente Sätze zu erzeugen. Diese Daten sollen ferner auch zu Verifikationszwecken dienen, also die KI-Ausgabe zu überprüfen und zu erkennen, an welcher Stelle noch nachtrainiert werden muss.
1.2 Entwicklung/Auswahl des Modells und Training/Lernen
Nach der Datenaggregation sowie der Aufbereitung der Daten erfolgt das eigentliche Training und somit das Lernen der KI. Dabei wird entweder ein selbst entwickeltes oder ein fremdentwickeltes und ggf. vortrainiertes KI-Modell verwendet und mit dem aggregierten Datensatz trainiert. Das Training kann, wie beschrieben, unüberwacht, überwacht oder in einer Mischform durchgeführt werden. Es ist notwendig, die Ergebnisse zu validieren, um etwaige Ungenauigkeiten zu detektieren.
1.3 Inhaltsgenerierung entsprechend dem Gelernten
Sobald das Modell erstellt bzw. trainiert wurde, ist es grundsätzlich in der Lage, mithilfe der entsprechenden Software neue Inhalte zu generieren. Dabei spiegelt generell der generierte Inhalt wider, was das Modell aus seinen Trainingsdaten und seinem Training gelernt sowie in seinen Zuständen abgespeichert hat. Auch in diesem Schritt sind die Ergebnisse eingehend zu validieren und ggf. die KI mit geänderten Parametern erneut zu trainieren.
1.4 Verfeinerung – Rückkopplung Selbstveränderung
Je nach Aufgabe und Anwendung können die generierten Inhalte immer weiter verfeinert oder nachbearbeitet werden, um ihre Qualität zu verbessern oder bestimmte Anforderungen zu erfüllen. Oftmals wird das alte Modell auch weiter genutzt und in einer Parallelhaltung das neue trainiert, danach das alte abgekündigt und das neue ausgerollt, es werden wieder neue Daten zusammengestellt, damit trainiert usw. Es handelt sich also um einen Kreislauf, der letztlich erst endet, wenn die KI-Anwendung stillgelegt oder nicht mehr genutzt wird.
Bezug zum Datenschutz?
Vor dem Hintergrund dieser vier Schritte ergeben sich Fragen zum KI-Design, die in erster Linie zwar an die Hersteller gehen, aber auch sehr wichtig für Nutzende sein können, die ja als Verantwortliche für ihre Daten verpflichtet sind, die Datenverarbeitung gem. Privacy by Design bzw. by Default im gesamten Lebenszyklen ihrer Daten zu gewährleisten. Daher können diese Fragen auch im Rahmen der Beschaffung an den Hersteller gerichtet werden und für die Auswahlentscheidung eine Rolle spielen.
Vor dem Hintergrund dieser vier Schritte ergeben sich Fragen zum KI-Design, die in erster Linie zwar an die Hersteller gehen, aber auch sehr wichtig für Nutzende sein können, die ja als Verantwortliche für ihre Daten verpflichtet sind, die Datenverarbeitung gem. Privacy by Design bzw. by Default im gesamten Lebenszyklen ihrer Daten zu gewährleisten. Daher können diese Fragen auch im Rahmen der Beschaffung an den Hersteller gerichtet werden und für die Auswahlentscheidung eine Rolle spielen.
2 Grundsätzliche datenschutzrechtliche Fragen beim KI-Design
Hersteller von KI-Anwendungen sollten sich gerade in der Designphase sehr umfassende Gedanken über die zu entwickelnde KI machen und dies dokumentieren. Denn dann ist man auch in der Lage, seinen Kunden entsprechende Informationen zu dem Produkt zur Verfügung zu stellen.
Dokumentation und Risikoanalyse
Dieses gilt besonders auch für Produkte aus gesetzlich bzw. normativ regulierten Bereichen wie Software-Medizinprodukte, bei denen eine solche Dokumentation sowie ein Risikomanagement zwingend vorgeschrieben sind. Gerade bei diesen medizinischen Produkten ist es essenziell, dass die „Zweckbestimmung der Datenverarbeitung” bereits umfassend festgelegt wird, denn dies hat wiederum große Auswirkungen auf das Design des Systems. Insbesondere sind die in solchen Systemen verwendeten Modelle (bspw. LLMs) zu definieren und diese einer umfassenden Risikoanalyse zu unterziehen. Ferner sollten auch die für das System getroffenen bzw. zu treffenden technischen und organisatorischen Maßnahmen definiert und dokumentiert werden. Darüber hinaus müssen auch die Umgebungsvariablen des KI-Systems usw. festgelegt werden, damit das System zielgerichtet und zweckgebunden eingesetzt werden kann. Gerade um eine Zweckbestimmung inklusive der Nutzeranforderungen zu definieren, sollte eine Stakeholderanalyse erfolgen. All dies sollte vom Hersteller/Anbieter dokumentiert werden, damit er dies als Dokumentenpaket dem Verantwortlichen bzw. dem Einsetzenden zur Verfügung stellen kann. Denn Letzterer ist in der Pflicht, die Rechtskonformität eines möglichen Einsatzes zu bewerten, wozu aussagekräftige Dokumente erforderlich sind.
Dieses gilt besonders auch für Produkte aus gesetzlich bzw. normativ regulierten Bereichen wie Software-Medizinprodukte, bei denen eine solche Dokumentation sowie ein Risikomanagement zwingend vorgeschrieben sind. Gerade bei diesen medizinischen Produkten ist es essenziell, dass die „Zweckbestimmung der Datenverarbeitung” bereits umfassend festgelegt wird, denn dies hat wiederum große Auswirkungen auf das Design des Systems. Insbesondere sind die in solchen Systemen verwendeten Modelle (bspw. LLMs) zu definieren und diese einer umfassenden Risikoanalyse zu unterziehen. Ferner sollten auch die für das System getroffenen bzw. zu treffenden technischen und organisatorischen Maßnahmen definiert und dokumentiert werden. Darüber hinaus müssen auch die Umgebungsvariablen des KI-Systems usw. festgelegt werden, damit das System zielgerichtet und zweckgebunden eingesetzt werden kann. Gerade um eine Zweckbestimmung inklusive der Nutzeranforderungen zu definieren, sollte eine Stakeholderanalyse erfolgen. All dies sollte vom Hersteller/Anbieter dokumentiert werden, damit er dies als Dokumentenpaket dem Verantwortlichen bzw. dem Einsetzenden zur Verfügung stellen kann. Denn Letzterer ist in der Pflicht, die Rechtskonformität eines möglichen Einsatzes zu bewerten, wozu aussagekräftige Dokumente erforderlich sind.
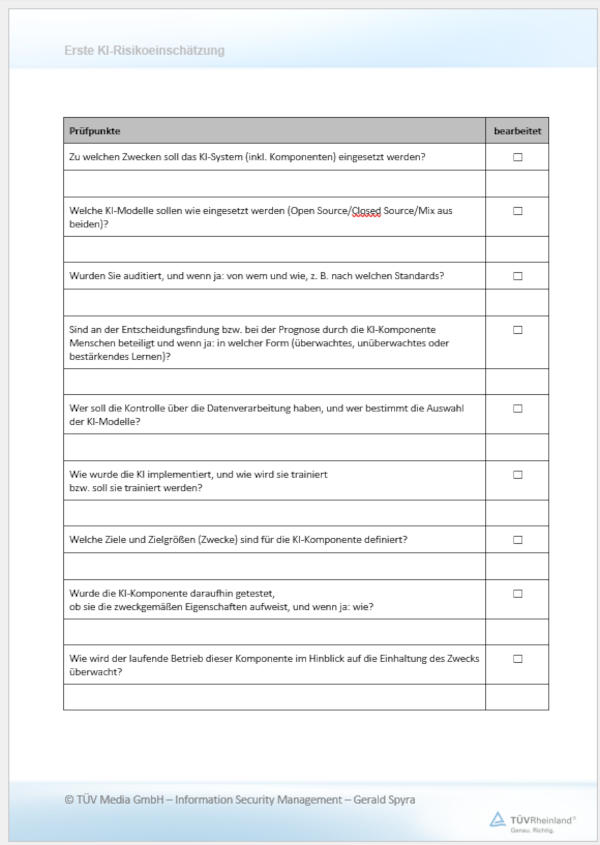
Grundfragen zur KI-Nutzung
Soll eine KI entwickelt oder eingesetzt werden, sind einige grundsätzliche Fragen stellen. Diese sollten alle dazu dienen, den konkreten Sachverhalt zu ergründen, um damit eine erste grobe Risikoeinschätzung vornehmen zu können. Denn im Artificial Intelligence Act (AI Act) [2] ist festgelegt, dass die Maßnahmen umso umfassender sein müssen, je größer die Risiken sind, um diese Risiken beherrschbar zu halten.
Soll eine KI entwickelt oder eingesetzt werden, sind einige grundsätzliche Fragen stellen. Diese sollten alle dazu dienen, den konkreten Sachverhalt zu ergründen, um damit eine erste grobe Risikoeinschätzung vornehmen zu können. Denn im Artificial Intelligence Act (AI Act) [2] ist festgelegt, dass die Maßnahmen umso umfassender sein müssen, je größer die Risiken sind, um diese Risiken beherrschbar zu halten.
